یادگیری تقویتی یا همان Reinforcement Learning چیست؟
سایر
5 دقیقه زمان مطالعه
آخرین به روز رسانی: 1404/06/20
یادگیری تقویتی (Reinforcement learning) یک متد آموزش ماشین یادگیری (machine learning) است بر این اساس که به رفتارهای مطلوب پاداش داده میشود و رفتارهای نامطلوب مجازات میشوند. به طور کلی، یک عامل (agent) یادگیری تقویتی میتواند محیط خود را درک و تفسیر کند، اقداماتی را انجام دهد و از طریق آزمون و خطا یاد بگیرد.
نویسنده: صبا خسرویان
0
0/10
2618
0
یادگیری تقویتی (Reinforcement learning) یک متد آموزش ماشین یادگیری (machine learning) است بر این اساس که به رفتارهای مطلوب پاداش داده میشود و رفتارهای نامطلوب مجازات میشوند. به طور کلی، یک عامل (agent) یادگیری تقویتی میتواند محیط خود را درک و تفسیر کند، اقداماتی را انجام دهد و از طریق آزمون و خطا یاد بگیرد.
یادگیری تقویتی یکی از رویکردهای توسعه دهندگان برای آموزش ماشین های یادگیری است. نکته ی مثبت یادگیری تقویتی (Reinforcement learning) این است که عامل در محیطی که باشد، چه یک ویژگی خاص در یک بازی ویدئویی باشد و چه یک ربات در محیط صنعتی باشد، و هر چقدر پیچیدگی داشته باشد، میتواند از محیط اطراف خود به کمک پاداش و مجازات آموزش ببیند و رفتارهای خود را بهینه کند.
تفاوت یادگیری تقویتی (Reinforcement learning) با سایر روشهای یادگیری ماشین
یادگیری تقویتی را میتوان شاخه ای از یادگیری ماشین در نظر گرفت. یادگیری تقویتی همزمان شباهت ها و تفاوتهایی با سایر روشهای یادگیری ماشین دارد. در ادامه سایر روش های یادگیری ماشین را به شما معرفی میکنیم که بتوانید تفاوتهای آنها را درک کنید.
یادگیری نظارتی آموزش دادن به یک عامل یادگیری ماشین با استفاده مجموعه ای از داده های برچسب گذاری است. برچسب های ارگانیک اغلب در داده ها در دسترس هستند، لمل این فرآیند ممکن است شامل یک متخصص انسانی باشد که برچسب هایی را به داده های خام اضافه میکند تا ویژگی های هدف (پاسخ ها) را به مدل نشان دهد. به زبان ساده تر، یک برچسب شامل توضیحاتی میشود که به مدل نشان میدهد که انتظار میرود چه چیزی را پیش بینی کند.
البته در نظر داشته باشی که این مدل ایراداتی نیز دارد از جمله این که :
1. سرعت پایین
سرعت این مدل پایین است زیرا نیازمند یک انسان متخصص است که که به صورتی دستی برچسب ها را به مدل تک به تک آموزش دهد و این کار زمان زیادی میبرد.
2. هزینه زیاد
یک مدل باید بر روی حجم زیادی از داده ها که به صورت دستی برچسب گذاری شده اند، آموزش ببیند تا بتواند پیش بینی های دقیقی ارائه کند.
یادگیری غیر نظارتی (Unsupervised learning)
یادگیری بدون نظارت در هوش مصنوعی نوعی از یادگیری ماشین است که عامل بدون نظارت انان ید میگیرد. برخلاف یادگیری تحت نظر، به مدل های یادگیری ماشین بدون نظارت داده های بدون برچسل داده میشود و به عامل اجازه میدهند الگوها و بینش هایی را بدون هیچ راهنمایی یا دستورالعمل صریحی کشف کنند.
یادگیری نیمه نظارتی (Semi-supervised learning)
یادگیری نیمه نظارتی ترکیبی از یادگیری نظارتی و غیر نطارتی است. در این مدل، یک مدل اولیه را روی چند نمونه برچسب دار آموزش میدهید و سپس به طور مکرر آن را روی تعداد بیشتری از داده های بدون برچسب اعمال میکنید. به بیان دیگر، از عامل خواسته میشود با توجه به برچسب هایی که آموزش دیده است، برای داده های بدون برچسب تصمیم گیری کند. در واقع از داده های برچسب دار آموزش میبیند و یاد میگیرد چگونه بهترین تصمیم را بگیرد.
یادگیری تقویتی (Reinforcement learning)
یادگیری تقویتی رویکرد متفاوتی نسبت به سه رویکرد بالا دارد. در این روش عامل در محیط قرار میگیرد و با آزمون خطا یاد میگیرد چه فعالیتی مطلوب و چه فعالیتی نامطلوب است و در نهایت به یک هدف مشخص میرسد. از این جهت که هدف مشخصی از یادگیری وجود دارد، مشابه یادگیری نظارتی است اما در این روش عامل آزادی عمل و انتخاب بیشتری دارد و با توجه به پاداش و مجازاتی که برای عامل در نظر گرفته میشود، الگوریتم مستقل تصمیم گیری میکند.
یادگیری تقویتی چگونه عمل میکند؟
در یادگیری تقویتی، توسعه دهندگان روشی برای پاداش دادن به رفتارهای مطلوب و مجازاتی برای تنبیه رفتارهای نامطلوب در نظر میگیرند. یادگیری تقویتی مقادیر مثبتی را برای رفتارهای مطلوب در نظر میگیرد تا عامل را تشویق به استفاده از آنها کند و ارزش های منفی برای رفتارهای نامطلوب در نظر میگیرد که عامل را از انجام این رفتارها دلسرد کند. به مرور زمان عامل یاد میگیرد که رفتارهای مطلوب بیشتری را انجام دهد و تصمیماتش بهینه شود و مدت زمان تصمیم گیری عامل برای راه حل بهینه کاهش یابد.
این اهداف بلند مدت به مرور زمان کمک میکند عامل در اهداف کم اهمیت گیر نکند و با گذشت زمان عامل یاد میگیرد که از منفی ها دوری کند و به دنبال مثبت ها باشد. این روش یادگیری در هوش مصنوعی (AI) به عنوان راهی برای هدایت ماشین یادگیری بدون نظارت از طریق پاداش و مجازات صورت میگیرد.
برای درک بهتر مسئله شکل 1 را در نظر بگیرید. عامل از نقطه S1 شروع میکند و با هر قدیمی که برمیدارد، امتیاز میگیرد. طبیعتا عامل باید به الماس برسد و باید از آتش دوری کند. وقتی به الماس میرسد کل امتیازها و پاداش را دریافت میکند و امتیاز نهایی عامل مشخص میشود و وقتی به آتش میرسد مجازات میشود و یک امتیاز از امتیاز نهایی عامل کم میشود.
عناصر اصلی یادگیری تقویتی
1. عامل یا یادگیرنده
2. محیطی که عامل با آن تعامل برقرار میکند
3. خط مشی که عامل دنبال میکند برای انجام عمل
4. جایزه ای که عامل در ازای عمل مطلوب دریافت میکند.
5. اقدام که تصمیمی است که عامل در پاسخ به یک حالت اتخاذ میکند.
6. حالت که وضعیت فعلی عامل را نمایش میدهد.
همین الان اگه احتیاج به سایت یا اپلیکیشن بر پایه هوش مصنوعی داری میتونی با مشاورین ما از طریق بخش تماس با ما تماس بگیری.
کاربردهای یادگیری تقویتی
استفاده از یادگیری تقویتی روز به روز در حال افزایش است و در آینده نیز افزایش می یابد. برخی از کاربردهای یادگیری تقویتی در عصر فعلی عبارتند از :
ربات های خودکار
هر چه رباتها از یادگیری تقویتی استفاده کنند، کارها را دقیقتر و سریعتر انجام میدهند. همچنین رباتها میتوانند کارهای خطرناکی را انجام دهند که برای انسانها خطرناک هستند. رباتها میتوانند با یک هزینه کم و بدون خستگی ساعات طولانی کار کنند. مثلا در برخی از رستورانها رباتها نقش گارسون را اجرا میکنند و غذا را به مشتریان میرسانند. همچنین برخی از شرکتها از رباتها برای مونتاژ محصولاتشان استفاده میکنند. رباتها برای موارد بسیاری استفاده میشوند و به مرور زمان استفاده از رباتها بیشتر و بیشتر میشود و کارآیی آنها بیشتر میشود و پتانسیل آنها برای انجام کارها افزایش پیدا میکند.
پردازش زبان طبیعی
متن پیش بینی کننده، خلاصه سازی متن، پاسخگویی به سوالات و ترجمه ماشین همگی نمونه هایی از پردازش زبان طبیعی (NLP) هستند که از یادگیری تقویتی استفاده میکنند. با مطالعه الگوهای زبان معمولی، عوامل یادگیری تقویتی میتوانند نحوه صحبت افراد را هر روز با یکدیگر تقلید کنند. این شامل زبان واقعی مورد استفاده و همچنین نحو (ترتیب کلمات و عبارات) و فرهنگ لغت انتخاب کلمات است.
بازاریابی و تبلیغات
هم برندها و هم مصرف کنندگان میتوانند از یادگیری تقویتی به نفع خود استفاده کنند. برندهایی که مخاطب هدف میفروشند، میتوانند به کمک یادگیری تقویتی پلتفرمهایی را طراحی کنند که از بهینه سازی تبلیغات استفاده کنند. بدین معنا که با کمترین قیمت، بهترین مخاطب را برای تبلیغات مد نظر کارفرما معرفی میکنند. برندها بدین طریق میتوانند متوجه شوند که کدام تبلیغات بازخورد بهتری دارند و مخاطب تمایل بهتری نشان میدهد.
از دیدگاه مصرف کنندگان مزیت یادگیری تقویتی این است که تبلیغات را از برندها و وب سایتهایی دریافت میکنند که معمولا از وب سایت آنها خرید کرده اند و یا تعامل نشان داده اند و در نتیجه تبلیغات شخصی و از برندها و محصولاتی دریافت میکنند که با آنها تعامل نشان داده اند.. هنگامی که این تبلیغ به کاربر نشان داده میشود، اگر کاربر بر روی تبلیغ کلیک کند، عامل امتیاز مثبت دریافت میکند و در صورتی که کاربر کلیک نکند، امتیاز منفی دریافت میکند و بدین طریق بهترین تبلیغات را به کاربر نشان میدهند.
پردازش تصویر
احتمالا شما هم تا به حال تست امنیتی انجام داده اید که از شما میخواهد اشیاء را در قابها شناسایی کنید (مانند انتخاب عکس هیی که شامل چراغ راهنمایی رانندگی هستند). این کار مشابه کاری است که ماشین یادگیری انجام میدهد، هر چند ماشین های یادگیری برخورد متفاوتی دارند.
هنگامی که از عوامل یادگیری تقویتی خواسته میشود یک تصویر را پردازش کنند،یک تصویر کامل را به عنوان نقطه شروع خود جستجو میکنندتا زمانی که همه چیز ثبت شود. سیستم های بینایی مصنوعی همچنین از شبکه های عصبی کانولوشنی عمیق که از مجموعه داده های بزرگ و برچسب گذاری شده تشکیل شده اند، برای نگاشت تصاویر به توصیف انسان از موتورهای شبیه سازی استفاده میکنند.
نمونه های دیگری از یادگیری تقویتی در پردازش تصویر عبارتند از :
• ربات هایی مجهز به حسگرهای بصری برای یادگیری محیط اطراف خود
• اسکنر برای درک و تفسیر متن
• پیش پردازش تصویر و تقسیم بندی تصاویر پزشکی، مانند سی تی اسکن
• تجزیه و تحلیل ترافیک و پردازش جاده در زمان واقعی با تقسیم بندی ویدئو و پردازش تصویر فریم به فریم
• دوربین های مدار بسته برای تجزیه و تحلیل ترافیک و جمعیت
سیستم های توصیه
عوامل یادگیری تقویتی میتوانند تشخیص دهند هر کاربر به چه چیزی علاقه مند است و مثلا از آن برای خواندن اخبار و یا توصیه اخبار به خواننده توصیه کرد. عوامل یادگیری تقویتی حتی میتوانند تشخیص دهند یک کاربر به چه موضوع یا حتی چه نویسنده ای علاقه مند است و مطالب مرتبط به وی توصیه کنند. تشخیص علایق کاربر شامل زمانی که روز یک مقاله میگذارد، تازگی خبر، میزان به شاتراک گذاشتن و ... است. سیستم های توصیه همچنین رفتارهای گذشته را برای پیش بینی آینده تجزیه و تحلیل میکنند. بنابراین اگر به عنوان مثال اگر صد نفر که فیلم X را مشاهده کردند، سپس فیلم Y را هم تماشا کردند و علاقه نشان دادند، احتمالا به کسانی که فیلم X را تماشا میکنند، مشاده فیلم Y را هم پیشنهاد میکند. اگر تبلیغات ناموفق باشد، ممکن است فیبم دیگری پیشنهاد کند و ببیند بازخورد چگونه خواهد بود تا به نتایج مطلوب برسد.
بازی
از مرحله ایجاد بازی جدید تا آزمایش باگ های آن و شکست در سطوح مختلف، یادگیری تقویتی یک منبع کارآمد و نسبتا آسان است که برنامه نویسان میتوانند به آن تکیه کنند. در مقایسه با بازی های ویدئویی سنتی که منطق بازی بر اسا درخت های رفتاری پیچیده بود، در بازی های جدید یادگیری تقویتی کمک بسیاری میکند. عامل یادگیری تقویتی در محیط بازی شبیه سازی اکشن های مختلف را یاد میگیر و از طریق آزمون و خطا اقدامات لازم را انجام میدهد و باگ های بازی را پیدا میکند و مشخص میکند که آیا ممکن است بازی در یک مرحله خاص گیر کند یا نه. عامل به راحتی بازی میکند و در مدت زمانی کوتاه تمام راه های ممکن برای انجام بازی را طی میکند و هر باگ یا ایرادی باشد را شناسایی میکند. این کار بدون دخالت انسان و استرس انجام میشود و در نتیجه بسیار دقیق است.
حفاظت انرژی
بسیاری از کشورهای جهان در حال تلاش برای کاهش استفاده از انرژی هستند که بتوانند اثرات آب و هوایی بد آنها را خنثی کنند. یک مثال واقعی این سات که شرکت های Deepmind و Google برای خنک کردن مراکز داده عظیمشان با یکدیگر فعالیت کردند و یک سیستم مبتنی بر هوش مصنوعی پیاده سازی کردند که نیازی به دخالت انسان ندارد و استفاده آن ها از مصرف انرژی 40% کاهش یافت. قابل توجه است که هر چند این سیستم بدون نیاز به دخالت انسان کار میکند، هنوز کارشناسانی بر روی عملکرد آن ها نظارت میکنند.
کنترل ترافیک
انسان سالهاست که با ترافیک دست و پنجه نرم میکند. یادگیری تقویتی کمک میکند که نقشه مجازی از شهر بسازیم و الگوهای ترافیکی را کنترل کنیم. عامل های یادگیری تقویتی میتوانند تشخیص دهند خودروها به کدام سمت میروند و در چه ساعات و روزهایی هر خیابان و مسیر شلوغ است و به رانندگان خودروها اطلاع دهد و آنها را راهنمایی کند که از مسیرهای کم ترافیک عبور کنند.
مراقبت های بهداشتی
یکی از راه های مهم برای استقرار یادگیری تقویتی، رژیم های درمان پویا است. برای تهیه یک رژیم درمانی پویا شخصی باید مجموعه ای از مشاهدات بالینی بیمار و ارزیابی های پزشکی بیمار را وارد کند و سپس با استفاده از نتایج قبلی و سابقه پزشکی بیمار، عامل پیشنهاداتی درباره نوع درمان، دوز دارو و جدول زمانبندی بیمار ارائه میدهد. این کار باعث سریعتر شدن روند درمان بیمار میشود.
چالش های به کارگیری یادگیری تقویتی
یادگیری تقویتی اگر چه فواید بسیار زیادی دارد، معایبی نیز دارد و چالش هایی را ایجاد میکند. ایجاد ئ نگه داری این ماشینها میتواند سخت و چالش پذیر باشد زیرا عاملین یادگیری تقویتی وابسته به اکتشاف محیط هستند. به عنوان مثال تصور کنید قصد دارید رباتی دارید را در یک محیط فیزیکی پیچیده مستقر کنید و در این محیط قرار است حرکت کند. ربات هر بار تلاش میکند حالت های مختلف را انجام دهد و اقدامات متفاوتی برای رسیدن به هدف انجام دهد. این عمل در دنیای واقعی بسیار سخت است زیرا یک محیط واقعی مداوم تغییر میکند و ثابت نیست بنابراین ربات مدام مجبور است اطلاعات قبلی که دارد را پاک کند و محیط جدید را درک کند و راه های جدید پیدا کند. زمان مورد نیاز برای اطمینان از انجام صحیح یادگیری از طریق یادگیری تقویتی سودمندی این روش را کم میکند. هر چه محیط پیچیده تر میشود، نیاز به زمان و منابع محاسبه نیز افزایش میابد. در چنین شرایطی شاید برای برخی شرکت هایی که منابع یادگیری (برچسب ها) کافی دارند، استفاده از یادگیری نظارتی کارآمدتر باشد زیرا با منابع کمتری ربات فضای اطراف را درک میکند.
الگوریتم های رایج یادگیری تقویتی
به جای استفاده از یک الگوریتم خاص، حوزه یادگیری تقویتی از چندین الگوریتم تشکیل شده است که رویکردهای متفاوتی دارند. تفاوت این الگوریتم ها عمدتا در استراتژی های مختلفی است که آنها برای کشف محیط اطراف خود استفاده میکنند:
1. state – action – reward – state – action (حالت – عمل – جایزه – حالت – عمل)
این الگوریتم یادگیری تقویتی با دادن چیزی که به عنوان یک خط مشی به عامل شناخته میشود. تعیین رویکرد بهینه مبتنی بر سیاست مستلزم بررسی اقدامات خاصی است که منجر به پاداش یا حالت های مطلوب میشود تا تصمیم گیری آن را هدایت کند.
2. یادگیری Q
این رویکرد برای یادگیری تقویتی رویکردی مخالف دارد. عامل هیچ خط مشی دریافت نمیکند و بر اساس کاوش در محیط، ارزش یک عمل را می آموزد. این رویکرد مبتنی بر مدل نیست، یبکه بیشتر بر خود عامل تکیه میکند. پیاده سازی های واقعی Q-learning اغلب با استفاده از برنامه نویسی پایتون نوشته میشوند.
3. شبکه های عمیق Q
این الگوریتمها همراه با یادگیری عمیق Q، علاوه بر تکنیکهای یادگیری تقویتی، از شبکههای عصبی نیز استفاده میکنند. آنها همچنین به عنوان یادگیری تقویتی عمیق نامیده می شوند و از رویکرد اکتشاف محیط خودراهبر یادگیری تقویتی استفاده می کنند. به عنوان بخشی از فرآیند یادگیری، این شبکهها اقدامات آینده را بر روی نمونهای تصادفی از اقدامات مفید گذشته قرار میدهند.
آینده یادگیری تقویتی
پیش بینی میشود که در آینده یادگیری تقویتی نقش بیشتری نسبت به هوش مصنوعی ایفا کند. روش های دیگر برای آموزش الگوریتم های یادگیری ماشین به مقادیر زیادی از داده های آموزشی از قبل موجود بستگی دارند. از سوی دیگر، عوامل یادگیری تقویتی به زمان نیاز دارند تا به تدریج یاد بگیرند که چگونه از طریق تعامل با محیط اطرافشان عمل کنند. با وجود چالش هایی که وجود دارد، انتظار میرود کمپانی های مختلف به بررسی پتانسیل یادگیری تقویتی ادامه دهند.
یادگیری تقویتی قبلا در زمینه های مختلف امیدوار کننده بوده است. به عنوان مثال، شرکت های بازاریابی و تبلیغات از الگوریتم هایی استفاده میکنند که به این روش برای موتورهای توصیه آموزش داده شده اند. سازندگان از یادگیری تقویتی برای آموزش سیستم های رباتیک نسل بعدی استفاده میکنند.
نمونهای از کاربرد یادگیری تقویتی در طراحی سایت و اپلیکیشنهای هوشمند
یکی از زمینههای جذاب برای استفاده از یادگیری تقویتی، طراحی سایتها و اپلیکیشنهای هوشمند است. هوش مصنوعی میتواند نقش بسزایی در بهبود تجربه کاربری (UX)، افزایش کارایی و حتی مدیریت خودکار سیستمهای سازمانی داشته باشد.
طراحی سایت با هوش مصنوعی
به عنوان مثال، یکی از پروژههای ما، اپلیکیشنی به نام اپلیکیشن زون است که با استفاده از الگوریتمهای هوش مصنوعی، فرایند حضور و غیاب کارکنان در سازمانها را به صورت خودکار مدیریت میکند. این اپلیکیشن با تحلیل رفتارهای کاربری، یادگیری از دادههای گذشته و پیشنهاد راهحلهای بهینه برای بهبود فرآیندهای اداری، تجربهای نوین از مدیریت منابع انسانی را ارائه میدهد.
ویژگیهای اپلیکیشن زون
دقت بالا در تشخیص حضور و غیاب: زون از ترکیب فناوریهای بینایی کامپیوتر و الگوریتمهای یادگیری تقویتی استفاده میکند تا حضور کارکنان را به طور دقیق شناسایی کند.
پیشنهادات بهینهسازی: با تحلیل دادهها، زون میتواند راهکارهایی برای افزایش بهرهوری سازمان ارائه دهد.
مدیریت خودکار: اپلیکیشن به گونهای طراحی شده است که نیاز به ورود اطلاعات دستی را به حداقل رسانده و فرایندهای مربوط به گزارشگیری را به صورت خودکار انجام میدهد.
یکپارچگی با سیستمهای سازمانی: قابلیت اتصال به سایر ابزارهای مدیریت سازمانی برای هماهنگی بهتر و دادهمحوری بیشتر.
ارتباط یادگیری تقویتی با طراحی سایت و اپلیکیشن
یادگیری تقویتی در طراحی این اپلیکیشن نقش کلیدی ایفا کرده است. الگوریتمهای یادگیری تقویتی با یادگیری از تعاملات کاربران و محیط، بهبودهای مداوم در تجربه کاربری و عملکرد سیستم ایجاد میکنند. این فناوری به ما امکان داد تا سامانهای بسازیم که نه تنها کارآمد است، بلکه میتواند به طور هوشمند با تغییرات محیط سازمان سازگار شود.
سخن نهایی
یادگیری تقویتی یا همان (Reinforcement Learning) به ماشین ها قدرت میدهد با آزمون خطا و دریافت جایزه در ازای رفتار مطلوب و مجازات در ازای رفتار نامطلوب بتوانند تصمیم گیری کنند و به مرور زمان تصمیم های بهتری اتخاذ کنند. یادگیری تقویتی میتوانند برای بسیاری از شرکت ها بسیار مفید و کاربردی است. شما میتوانید با توجه به نیازتان، با شرکت اُرُد از طریق این لینک ارتباط برقرار کنید و سفارش طراحی سایت، اپلیکیشن و یا وب اپلیکشن های مبتنی بر یادگیری تقویتی بدهید.



 بیشتر بخوانید:
بیشتر بخوانید: 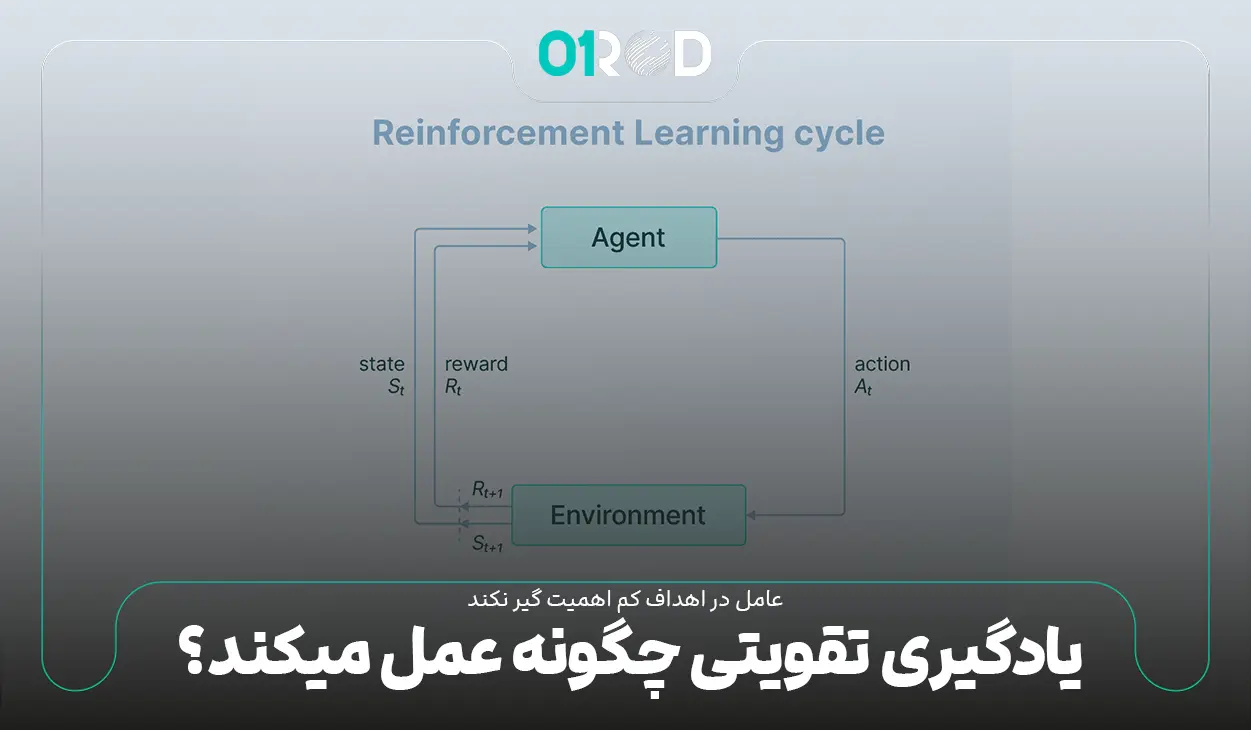



برایپروژهضروریاست؟.webp) سایر
سایر




افزودن دیدگاه
متاسفانه نظری برای نمایش وجود ندارد. اولین نفری باشید که نظر میگذارد!
افزودن دیدگاه